




Most people who file their income tax return through a CA have never actually read what got submitted. You sign the return, the CA files it, and you find out what’s inside only if something comes back queried.
BRSR XBRL works the same way.
The PDF version of the report is reviewed line by line by the board, sustainability, legal, and often the Big 4.
But the XBRL version, the one SEBI, stock exchanges, rating agencies, and ESG data platforms actually read gets a quick glance before it is signed off and uploaded.
That mismatch is not harmless. It is where FY 2026 filings are already starting to break.
Because the machine-readable version is what flows into every downstream system – from SEBI’s analytics layer to ESG ratings and investor screens. If something is tagged incorrectly, it does not stay a formatting issue. It becomes a data issue.
And under BRSR Core, that data is now being assured. In fact, KPMG’s February 2026 review of 94 large, listed companies shows that reasonable assurance on BRSR Core is rapidly becoming standard at the top end of the market.
If you’re the one signing off on BRSR filings, this ten-minute read could save you weeks of rework later. Here’s what you’ll walk away with:
- How the BRSR XBRL taxonomy is actually structured
- Where operational data breaks on its way into XBRL tags
- The validation errors NSE has flagged in FY 2026 filings
- What BRSR Core and value chain disclosures change from here
Why BRSR XBRL Matters More Than the PDF (And Why Most Teams Still Don’t Know This)
Here’s the thing most listed companies get wrong about BRSR filings. They think of the PDF as the report and the XBRL as the paperwork.
It’s the other way around.
The PDF is the human-readable version — it’s what the board reviews, what goes into the annual report, what investors skim if they skim anything. It matters for narrative and disclosure quality.
But almost nothing downstream actually parses the PDF. The XBRL is what every automated system reads.
- When SEBI runs cross-sector ESG analytics, it’s parsing the XBRL. In fact, when XBRL International had analysed over 1,000 BRSR filings in its India white paper, each instance document carried roughly 1,600 tagged data points — each one of them machine-readable, comparable, and extractable.
- When Refinitiv, Morningstar Sustainalytics, or any ESG data aggregator builds a scorecard for your company, they’re ingesting the XBRL, not reading your narrative.
- When a rating agency downgrades your environmental score because your emissions intensity looks like an outlier versus peers, they’re comparing structured, tagged numbers — yours against everyone else’s.
And under SEBI’s Listing Obligations and Disclosure Requirements, both formats have to be filed on the same day, with the same underlying numbers. The rule is simple.
The reality is that PDF and XBRL versions drift apart through the review cycle, and nobody does the final reconciliation because the people reviewing the PDF and the people generating the XBRL are usually not the same team.
Which means the number your board approved in the PDF and the number your assurance provider will verify in the XBRL are often, quietly, not the same number.
To understand why these two versions drift — and why the XBRL is where the drift hides — you have to look at how the taxonomy is actually built.
Inside the BRSR XBRL Taxonomy: How the Structure Actually Works
Before you can understand why BRSR XBRL filings break, you need to understand what’s actually under the hood. Not because the technical detail is fascinating — it isn’t — but because most filing errors trace back to three things the compliance team never had the vocabulary to ask about.
What the BRSR XBRL Taxonomy Actually Is
The BRSR XBRL taxonomy is a regulator-issued data dictionary that defines every disclosure item in the Business Responsibility and Sustainability Report — what it’s called, what type of data it accepts, what units it expects, and where it sits in the reporting structure.
Think of it as a form with very strict rules about what you can write in each box. Some boxes accept only numbers in specific units. Some accept text up to a certain length.
Some are mandatory. Some are conditional — they only need to be filled if another box says yes. The taxonomy is the document that specifies all of that.
SEBI sets the disclosure requirements through its July 12, 2023 BRSR circular and subsequent updates. NSE and BSE translate those requirements into the actual XBRL schema and host the filing infrastructure.
When SEBI updates a disclosure — as it has repeatedly through BRSR Core — the taxonomy version changes, and your filing tool must catch up.
Taxonomy, Instance Document, and Utility — The Three Things Filers Confuse
Most people who’ve signed off on a BRSR XBRL filing can’t cleanly distinguish between these three terms. It matters, because when something breaks, you need to know which one broke.
The taxonomy is the dictionary — the set of rules. It lives on the NSE and BSE servers and gets updated periodically.
The XBRL instance document is your company’s actual filing. It’s an XML file that contains your tagged data — every number, every narrative disclosure, every “yes/no” — mapped against the taxonomy’s definitions.
The BRSR XBRL utility is the tool NSE and BSE provide to generate that instance document without hand-writing XML. It’s essentially a structured form that takes your inputs, validates them against the taxonomy, and produces a valid instance document you can upload.
One detail worth knowing, as per NSE’s filing guidelines, the utility is compatible across both exchanges. If you’re dual-listed on NSE and BSE, you can use either exchange’s utility to upload on either portal.
Many compliance teams don’t know this and end up running the same filing twice through different tools.
What Gets Tagged, What Doesn’t, and the Field Everyone Forgets
An XBRL instance document carries two kinds of content: numeric facts and narrative disclosures.
Numeric facts are the quantitative data points — energy consumption in joules, water withdrawal in kilolitres, waste generated in metric tonnes, GHG emissions in CO₂e, gender ratios as percentages, wages paid in rupees.
Each one gets tagged with its value, its unit of measurement, its reporting period, and its context reference (which entity it applies to, which scenario, which scope).
Narrative disclosures are the qualitative fields — policy statements, governance descriptions, stakeholder engagement summaries, grievance redressal narratives. These get tagged too, but as text blocks rather than numeric values.
And then there’s the field everyone forgets: “Add Notes”. For any disclosure that doesn’t apply to your industry — certain waste categories for financial services firms, specific labour disclosures for asset-light businesses — the taxonomy requires you to state the non-applicability explicitly, with a reason, inside the XBRL itself.
Leaving this field blank in the XBRL while explaining the non-applicability only in the PDF is one of the most common tagging failures SEBI and the exchanges see. More on that shortly.
At scale, a single BRSR XBRL filing ends up carrying roughly 1,600 tagged data points across numeric and narrative fields. That’s 1,600 places where something can go quietly wrong.
Technical Mapping: From Operational Data to XBRL Tags
Here’s where compliance teams consistently underestimate the work.
Your operational data doesn’t arrive in XBRL-ready form. It arrives in the units your plant uses, the formats your HR system exports, the spreadsheets your procurement team maintains.
The taxonomy expects something more specific — a defined unit, a defined data type, a defined structure. And the layer between those two realities is where most filing errors are quietly introduced.
The table below shows the most common mapping points that trip filers up.
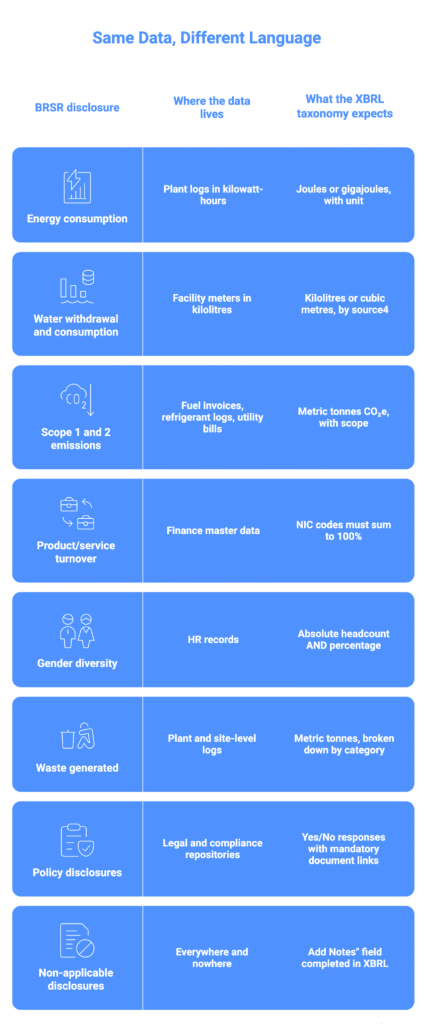
Each row in that table is a handoff. And each handoff is usually happening in a spreadsheet, three days before the filing deadline, managed by whoever had the bandwidth to do it.
That’s the fragile part of the process.
- Your plant sends monthly energy data in kWh. Someone converts it to gigajoules — or forgets to.
- Your HR team exports headcount as absolute numbers. Someone calculates the percentage — or leaves the field blank.
- Your finance team provides turnover by product line. Someone maps it to the current NIC code schedule — or uses last year’s codes, which were revised.
None of this is complicated work. It’s just invisible work. And when it’s done in a spreadsheet by a rotating cast of interns, analysts, and outsourced XBRL vendors, the audit trail is “whatever” someone remembers when asked three months later.
The stronger setups skip that handoff entirely. Source documents like invoices, meter readings, HR exports, and procurement data get ingested directly into the reporting layer, with OCR and language models handling the extraction.
The unit conversion happens inside the system, against the live taxonomy version. The number that ends up in the XBRL instance is traceable back to the specific invoice, meter log, or export it came from. No spreadsheet in the middle, no silent rounding, no manual rekey.
This is also where platforms like Credibl quietly do most of their work. Not in the final filing, but in making sure the number in the filing matches the number on the source document that produced it.
Because under BRSR Core assurance, that traceability isn’t a nice-to-have anymore. It’s what the auditor opens with.
The Validation Errors Breaking FY 2026 BRSR XBRL Filings
Most BRSR XBRL filings don’t get rejected at upload. They get accepted with observations, filed on time, and the problems only surface later, when an assurance provider, rating agency, or SEBI’s analytics layer starts reading the tagged data.
Every error below has been documented by NSE, flagged by assurance reviewers, or inferred from the restatement patterns visible in FY25 filings. None of them are theoretical.
Putting Energy in the Wrong Units
The most common validation error is also the most basic. NSE’s observations circular from May 2024 flagged companies disclosing energy in units other than joules, and in some cases not specifying the unit at all.
Why it happens?
Plant data arrives in kilowatt-hours because that’s what the meter shows. Nobody in the filing chain converts it. NSE eventually added a unit dropdown to the utility specifically because so many filings were ambiguous.
Why it matters?
Emissions intensity ratios are meaningless when the denominator is in the wrong unit. Once you’ve filed with the wrong unit, every year-on-year comparison afterward is broken.
NIC Codes That Don’t Sum to 100%
Product and service turnover, broken down by NIC code, must total exactly 100%. NSE has flagged filings showing 97%, 103%, or a mix of obsolete and current codes.
Why it happens?
NIC codes get revised. Product lines change. Nobody reconciles the classification before filing, because it’s treated as a data-entry task.
Why it matters?
SEBI uses NIC codes to benchmark you against sector peers. Wrong codes mean you’re being compared to the wrong peer set, and rating agencies downstream have no way to know.
Absolute Numbers Where Percentages Were Asked
NSE’s circular flagged attrition reported as raw headcount instead of a percentage. Gender ratios submitted as absolute counts without the required percentage field. Some disclosures require both and filings provided only one.
Why it happens?
A PDF narrative can say “women make up 34% of our workforce, or 2,140 of 6,294 employees” and both numbers feel interchangeable. XBRL fields are typed. A percentage field won’t accept a raw count cleanly.
Why it matters?
Every data aggregator builds ratios from your tagged facts. If the expected ratio is already in your filing but you’ve submitted a raw count, every downstream calculation is off.
The “Add Notes” Field That Everyone Skips
When a disclosure isn’t applicable to your industry, the taxonomy requires you to state the non-applicability inside the XBRL, in the “Add Notes” field, with a reason. Most filings explain it beautifully in the PDF and leave the XBRL field empty.
Why it happens?
The PDF and XBRL are often generated by different teams. The PDF gets the thoughtful treatment. The XBRL gets the minimum viable tagging.
Why it matters?
When an analyst, rating agency, or SEBI system parses an empty field, they don’t see your PDF’s explanation. They see a non-response, scored as a disclosure failure.
The PDF and the XBRL Don’t Agree
This is the big one. The PDF narrative gets revised in week two of filing prep. The XBRL gets regenerated in week four. Somewhere in between, the numbers drift.
KPMG’s February 2026 review of 94 NIFTY 100 companies found that 45 of them restated their comparative FY24 BRSR figures in their FY25 reports.
Why it happens?
The attributes most commonly restated included energy consumption, GHG emissions, PPP-adjusted intensity ratios, and concentration of purchases and sales. Many of these restatements were triggered by SEBI’s December 20, 2024, circular on Industry Standards Forum guidance for BRSR Core.
Why it matters?
A restatement is a signal. It means the number you filed last year isn’t the number you’re standing behind this year. Under BRSR Core assurance, restatements get examined.
The auditor wants to know why the figure moved, which version was right, and whether the PDF and XBRL both reflect the corrected number. If they don’t, you’re explaining it for the next three weeks.
Taxonomy Version Drift
NSE and BSE periodically update the BRSR XBRL utility. New fields appear when SEBI amends a disclosure.
Validation rules tighten when the exchanges see enough bad data to build a rule against it.
Why it happens?
Most compliance teams download the utility once a year, in the week before filing. If the taxonomy moved since last year, they find out by failing validation.
Why it matters?
Validation failure in the final week is the worst possible time to discover a problem. And if you’ve outsourced the XBRL conversion to a vendor using last year’s templates, you’re getting last year’s filing format wrapped in this year’s data.
The common thread across all six errors is the same. None of them are caused by the taxonomy being hard. They’re caused by nobody having line-of-sight into what’s actually been tagged, until it’s too late to fix.
What BRSR Core Changes for XBRL in FY 2026 and Beyond
The BRSR XBRL filings being submitted in FY 2026 aren’t just being tagged differently. They’re being read differently.
Three shifts are converging at the same time, and each one puts more pressure on the tagging layer.
Assurance expansion
Reasonable assurance on BRSR Core has already become standard at the top end. SEBI’s phased roadmap takes that same bar down the market capitalisation ladder through FY 2026-27, eventually covering the Top 1,000 listed entities.
Which means every validation error that used to be an internal annoyance now sits inside the auditor’s scope.
Value chain disclosures entering XBRL scope
Under SEBI’s revised framework, the Top 250 listed entities are expected to report ESG data from value chain partners covering 75% of purchases and sales, filtered through the 2% de minimis threshold.
These disclosures are voluntary for FY 2025-26 and assurance-voluntary from FY 2026-27, but the taxonomy already has fields for them.
Filers who’ve spent the last three years figuring out how to tag their own operations are about to add supplier data to the same instance document.
Framework convergence
A January 2026 policy brief from the Observer Research Foundation, drawing on an October 2025 roundtable with SEBI, industry, investors, and regulatory experts, makes the direct argument that India needs a unified digital taxonomy allowing companies to file once and serve BRSR, ISSB, and GRI.
SEBI’s public direction points the same way. For compliance teams, that means the BRSR XBRL taxonomy is going to keep moving, and each move will add fields, tighten validation rules, and increase the number of places where last year’s filing format breaks.
Treating BRSR XBRL as Data, Not Paperwork
BRSR XBRL is being treated as a file to submit, not as data to manage.
The numbers in the XBRL instance are the same numbers the dashboards show, the same numbers the auditor will trace, the same numbers the CFO reviewed three months before the deadline. Nothing is generated at the last minute, because nothing needs to be.
This is the architecture Credibl is built on. Source documents get ingested into a single reporting layer. Tagging happens against the live taxonomy version, with every data point linked back to the invoice, meter log, or export it came from.
When an assurance provider asks where a specific number originated, the answer is one click away. And because the same data serves the PDF narrative, the XBRL instance, and the audit trail simultaneously, the three versions don’t drift.
The taxonomy isn’t what’s breaking BRSR XBRL filings. The visibility into what’s been tagged is.
BRSR XBRL doesn’t fail loudly. It fails in the silence between the PDF your board signed and the tagged data the regulator actually reads. Book a demo to see how Credibl closes that gap.
FAQs
1. What is BRSR XBRL?
BRSR XBRL is the machine-readable version of the Business Responsibility and Sustainability Report, filed by listed Indian companies with SEBI through NSE and BSE. It uses a regulator-issued taxonomy to tag every disclosure as structured data, which is what rating agencies, ESG data platforms, and SEBI’s own analytics layer actually read. The PDF is the narrative. The XBRL is the record.
2. Is BRSR XBRL filing mandatory in India?
Yes. Under SEBI’s Listing Obligations and Disclosure Requirements, the top 1,000 listed entities by market capitalisation must file their BRSR in both PDF and XBRL formats on the same day they submit their annual report. The XBRL filing is not optional, and cannot be substituted by the PDF alone.
3. What is the difference between BRSR PDF and BRSR XBRL?
The BRSR PDF is the human-readable narrative version that goes into the annual report. The BRSR XBRL is the structured, tagged version parsed by SEBI, exchanges, rating agencies, and ESG aggregators. Both must contain the same underlying numbers, but because they are often prepared by different teams, the two versions frequently drift during the review cycle.
4. Can the BSE BRSR XBRL utility be used for NSE filings?
Yes. Per NSE’s filing guidelines, the BRSR XBRL utility is compatible across both exchanges. A dual-listed company can use either NSE’s or BSE’s utility to generate the instance document and upload on either portal, which removes the need to run the same filing twice through different tools.
5. What are the most common BRSR XBRL validation errors?
The most commonly flagged errors include energy data reported in non-joule units, NIC codes that don’t sum to 100%, absolute numbers submitted where percentages were required, blank “Add Notes” fields for non-applicable disclosures, and mismatches between the PDF narrative and the XBRL instance. NSE’s May 2024 observations circular documents most of these as recurring patterns across listed entity filings.
6. What happens if the BRSR PDF and BRSR XBRL versions don’t match?
Under BRSR Core assurance, assurance providers compare both versions and flag every place they don’t align. A mismatch doesn’t cause an upload rejection, but it triggers auditor queries, potential restatements in the following year, and downstream issues with rating agencies and data aggregators that parse the XBRL directly.
7. Can a BRSR XBRL filing be revised after submission?
Yes. NSE and BSE allow revision of both the PDF and XBRL, though the exchanges explicitly recommend using this option sparingly. Frequent revisions raise flags during assurance review and undermine the comparability of year-on-year disclosures.
8. How does BRSR Core change XBRL filing requirements?
BRSR Core introduces reasonable assurance on a defined set of ESG attributes, with the requirement expanding from the top 150 listed entities in FY 2024-25 to the top 1,000 by FY 2026-27. It also adds value chain disclosures to the taxonomy. This shifts the XBRL from a filing exercise to an audit-reviewed data record, where every tagged number must be traceable to a source document.